Kafka Stream
Kafka Streams是一个客户端lib库,其中输入和输出数据存储在Kafka集群中,主要应用在简单、轻量的流式ETL操作。
Kafka Stream的特点包括:
简单轻巧的客户端库,可以非常方便的嵌入的任意JAVA程序中,并且无需依赖任何kafka之外的服务。
通过Kafka的Partition机制水平扩展
支持有状态操作,如包括 Aggregate算子、Windows算子、Join算子等
支持 exactly-once 语义(可以按照需要配置为at-least-once)
毫秒级延时,支持基于event-time的窗口操作
提供必要的流处理元语、high-level Streams DSL(提供Map、Filter、Join等高级API) 、 low-level Processor API(提供API用于用户定制功能)
分布式实现
Kafka Stream 利用 Kafka 本身的分区机制来实现并行任务,Streaming 中任务被分成多个 Task,每个Task处理一个或者多个Partition上的数据。
用户可以对同一个任务启动多个实例,这些实例中通过 application.id 来辨识是否属于同一个任务。一旦某个实例失败,该实例上的task会在其他实例上恢复,并且继续工作。
Kafka Streaming在不同task之间不进行数据共享,因此进行聚合等操作时Stream任务会发生re-partition,同时join等操作也会有一些限制。
Streams DSL
Streams DSL是在进行Kafka Stream开发中使用的主要API,包括了以下三个抽象概念:
KStream:KStream是record stream的抽象,表示对一个或多个partition中的数据。
KTable:KTable本质上是一个changelog stream,每条流入的记录相当于对KTalbe进行一次Update、INSERT操作。当一条记录的value为null时,表示删除DELETE记录操作。在KTable中Key是唯一的!
GlobalKTable:与KTable的区别在于GlobalKTable获取所有partition中的数据,保存到Application的本地,而KTable只保存当前Application中处理的partition数据。GlobalKTable可以用作Application中的broadcast功能。
Stateless常用算子
Stream中算子是强类型操作,进行所有Transform操作时均需要指明算子的输入/输出类型。
Stateless 算子,不要求State Store来存储中间状态,用户可以将结果转换为一张无状态的KTable中来进行交互式的查询。
| 算子 | 说明 |
|---|---|
| Branch | 根据指定逻辑将Stream分成一个或者多个,应用的场景类似于代码中的switch语法 |
| Filter | 过滤KStream或者KTable对象中的Record |
| Inverse Filter | 和Filter相反,删除返回True的元素 |
| FlatMap | 将一条Record变为多条,如果flatMap之后的操作是join或者group,那么让Stream发生repartition |
| FlatMap (values only) | 在key不变的情况下将一条Record分为多条,通常不会造成re-partitioning |
| Peek | 遍历每条记录,但是不改变其值,应用该操作的边际效应 |
| Foreach | Terminal operation.返回值为void |
| Terminal operation.打印(key+”, “+value) | |
| Map | 改变Stream的Key和Value |
| Map (values only) | 改变Stream和Ktable的Value取值 |
| Merge | 合并两个Stream的每条记录,保证合并的相对顺序 |
| SelectKey | 改变Key的值或者类型 |
| GroupByKey | KStream → KGroupedStream |
| GroupBy | 相比GroupByKey可以改变Key的取值和类型(对于Stream可以改变Key的类型,对于Table既能改变类型和取值),相当于selectKey(…).groupByKey()的连续应用 |
Stateful算子
Stateful算子需要使用“state store”来存储中间数据,state stores 的实际实现可以是kv存储、内存中的hashmap、某种数据结构。Kafka允许Stream之外的程序访问该 stream 程序创建的 state stores,这种能力是Kafka实现 Interactive Queries 的基础。
DSL中包括以下几种有状态算子:
- Aggregating
- Joining
- Windowing
- 其他自定义类型
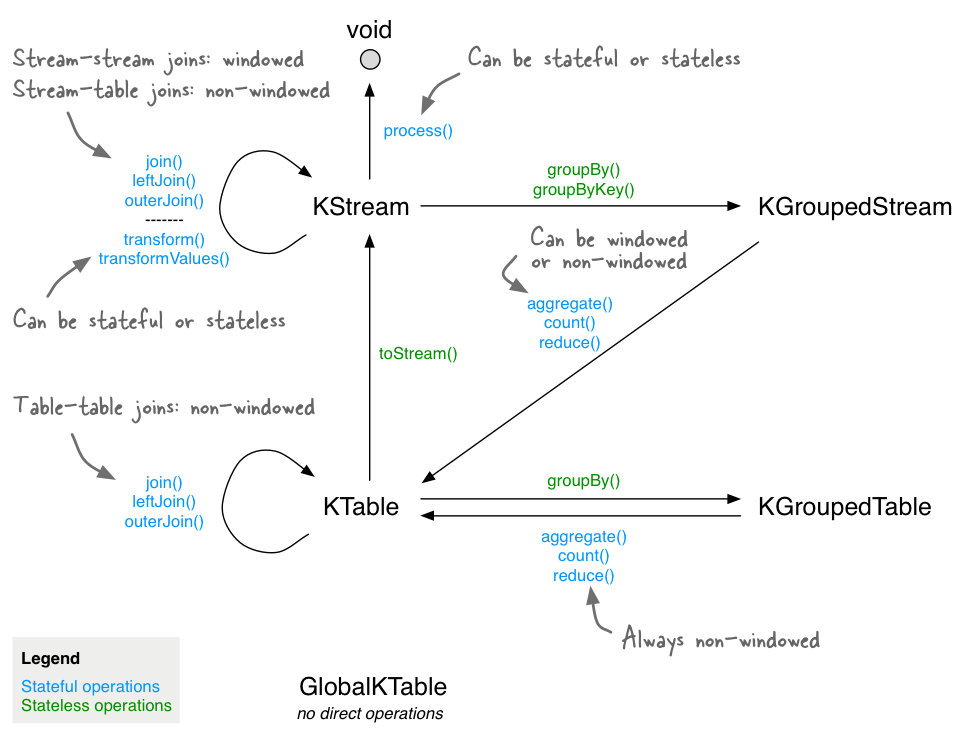
Aggregating
Aggregating对于KGroupedStream和KGroupedTable由groupBy算子产生,可以在其后使用聚合类型的算子。这一类算子基于KV类型进行操作,并在相同的Key的Record上进行操作,最终生成一个KTable类型的对象。
Aggregating包括:Aggregate算子、Reduce算子、Count算子三种类型,并且支持窗口操作。
Aggregate算子对 KGroupedStream、KGroupedTable 进行滚动聚合操作,并产生KTable。使用时提供initializer 、adder、subtractor(只有操作KGroupedTable时需要提供)三种接口。
对象为 KGroupedStream 遵循下面的逻辑:
- null keys 的记录直接被丢弃
- first Keys 到达时先调用initializer,之后调用adder
- 随后相同Key到达时调用adder
对象为 KGroupedTable 遵循下面的逻辑:
- null keys 的记录直接被丢弃
- first Keys 到达时先调用initializer,之后调用adder(相当于INSERT操作)
- 随后相同Key到达时先调用subtractor,之后调用adder(相当于UPDATE操作)
- null value 相当于DELETE操作,调用subtractor,并且移除表的KEY
Aggregate算子如果跟在windowedBy操作之后,则变为窗口形式。只针对当前窗口Record进行聚合。
Join
在Kafka中执行Join操作基于 leftRecord.key == rightRecord.key 来进行。
由于Kafka Stream的Task中只能获取部分Partition的数据,所以如果想要获取正确的Topic结果需要满足data co-partitioning条件,即:
- 输入的Topic要有相同数目的分区
- 所有Input Topic的分区策略必须稳定,并且能够保证相同Key被路由到相同分区
支持的Join类型包括:join、leftJoin、outerJoin,并且根据左右对象的不同可以分为以下场景:
- KStream之间Join
- KTable之间Join
- KStream和KTable之间Join
- KStream-GlobalKTable Join(无需满足data co-partitioning条件)
对Kafka来说整个Join过程是流式进行的,并非在窗口内缓存数据一批执行一次join。
官方文档给出了各种情况下join结果的表格(参考)。
Windows
windows的作用和group算子类似,group算基于key对record分类,而windows则基于时间对record进行分类。同一个窗口的数据被保存在state store中,直到该窗口过期。
Windows并非在要失效后触发操作,而是每当有数据进入窗口时触发一次action。但是也可以使用suppress来抑制窗口的action
Kafka支持以下四种窗口:
- Tumbling time window:翻滚窗口
- Hopping time window:实际意义上滑动窗口
- Sliding time window:特殊的滑动窗口,是非对齐的,只能用在join操作上
- Session window:根据相同Key记录出现的时间间隔来划分窗口
大部分类型的windows划分基于时间,Stream在KafkaStream中包括以下三种时间:
- Event time:事件时间
- Processing time:Stream处理记录的时间
- Ingestion time:摄入时间,即数据被写入到Kafka的时间
Kafka会自动为记录嵌入一个时间戳,用户可以在broker或者topic上配置该时间的含义。
在Kafka Stream中,Processor会根据实际情况为生成的records分配时间戳,包括:继承原有timestamp、以当前时间生成新timestamp、聚合操作中继承最后一条record的timestamp。
在Kafka Stream中按照Offset而不是TimeStamp顺序来处理数据,因此对于有状态操作不能保证Record是按照时间顺序来处理的。
开发Tips
依赖
使用Kafka Streaming时需要包括以下三个依赖,其中最后一个依赖只有使用scala开发时需要添加(CDH版本同样有这三个依赖)。
1 | <dependency> |
配置项
参考官方文档
| 配置项 | 说明 |
|---|---|
| application.id | 用于标识Streaming的应用名称。在整个kafka集群中,相同application.id的进程视为一个集群,任务在这些进程中自动均衡。该配置还被用于充当任务的group.id,client.id的前缀,内部topic的前缀,以及一些streaming子目录的前缀。 |
| default.deserialization.exception.handler | 处理序列化异常 |
| default.production.exception.handler | 处理Streaming程序和Kafka broker的交互异常 |
| default.key.serde/default.value.serde | 默认序列化类 |
| num.standby.replicas | task的副本数目,指local state stores的副本数目,对于n个部分的实例,需要配置n+1个Kafka Stream实例。 |
| partition.grouper | 决定task和partition的映射机制 |
| processing.guarantee | at_least_once、exactly_once |
| replication.factor | streaming 内部topic的副本数目 |
| state.dir | 用来存储local states的目录 |
| timestamp.extractor | 从Record中抽取时间戳的Class,支持FailOnInvalidTimestamp、LogAndSkipOnInvalidTimestamp、UsePreviousTimeOnInvalidTimestamp、 WallclockTimestampExtractor |
| rocksdb.config.setter | rocksdb的配置,rocksdb被用来作为Kafka Streaming的持久化存储工具 |
Kafka Connect
Kafka Connect 是Kafka和其他系统间的数据管道,支持分布式、单机两种模式部署。用户在配置文件中指定Connectors类,Kafka通关这些Connectors类连接外部系统来传输数据(做的事实际上有点像Flume)。
Kafka 中包括 SourceConnectors 、SinkConnectors 两种类型的Connectors,每个Connectors中包含多个Task,这些Task映射到外部系统的一批数据(比如一张表、文件),是实际的工作执行者。
官网说明了用户应该如何开发一个Connectors,内容包括:接口实现、Offset管理、动态配置、配置文件校验、Schemas、任务启停等等。
相比用户直接用Consumer、Producer的SDK去开发业务,使用Kafka Connect有下面几个优势:
- 实现一个统一框架,遵循框架来开发能提高代码的质量
- 有一套 REST API 接口,可以实现传输任务的启动、停止、删除的操作
- 自动化的Offset管理
- Confluent.IO可以获取许多线程实现
总结
当业务以Kafka作为主要数据源(Kafka流处理平台)时,KStream、Kafka Connect能发挥最大价值,对当前IData来说这两个功能比较鸡肋。
KStream 是一种较为轻量的流处理框架(功能更少的Flink or Spark),可以用于取代当前IData的部分Spark Streaming业务,能够获得一定的性能提升。但是要在IData中完全引入流式处理的框架,可能需要对业务有大量的修改。
Kafka Connect 生态比较丰富,一些ETL、南北向接口的场景可能值得一用。
